What causes overfitting in models?
The moment a machine learning model performs brilliantly on the data it was trained on but fails miserably when presented with new, unseen examples, you are witnessing overfitting in action. [5][7] It is a situation where the model has learned the training data too well—it hasn't just captured the underlying patterns; it has also memorized the random noise and specific idiosyncrasies present only in that training set. [1][6] This results in a significant gap between the model's performance on training data (very low error) and its performance on test or validation data (high error). [7] Understanding the root causes behind this phenomenon is essential for building models that generalize reliably to the real world. [6]
# Model Capacity
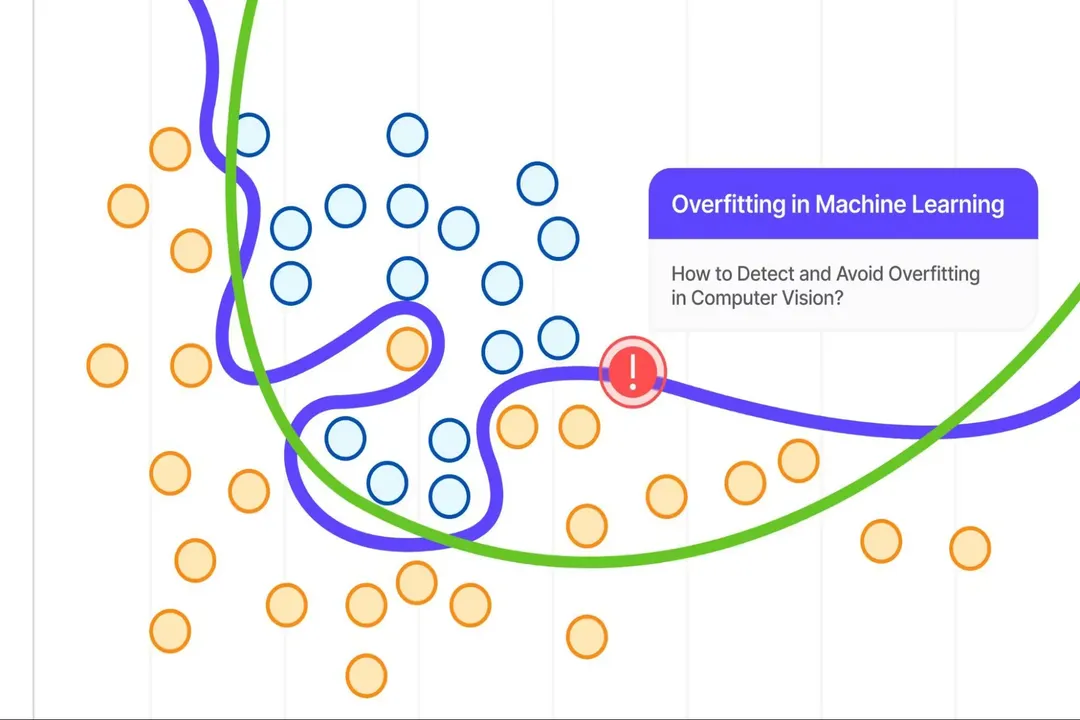
The most direct cause of overfitting relates to the complexity, or capacity, of the model itself relative to the data it is trying to learn. [1][6] A highly flexible model, such as a deep neural network with an excessive number of layers or neurons, or a decision tree allowed to grow without restraint, possesses too many parameters or "degrees of freedom". [6]
When a model has high capacity, it can afford to create a unique, highly specific rule for almost every single data point in the training set. [5] Instead of learning a smooth, general relationship between features and the target variable—say, a straight line or a gentle curve—the overfit model twists and turns its decision boundary to perfectly encompass every single training point, including the outliers and measurement errors. [7]
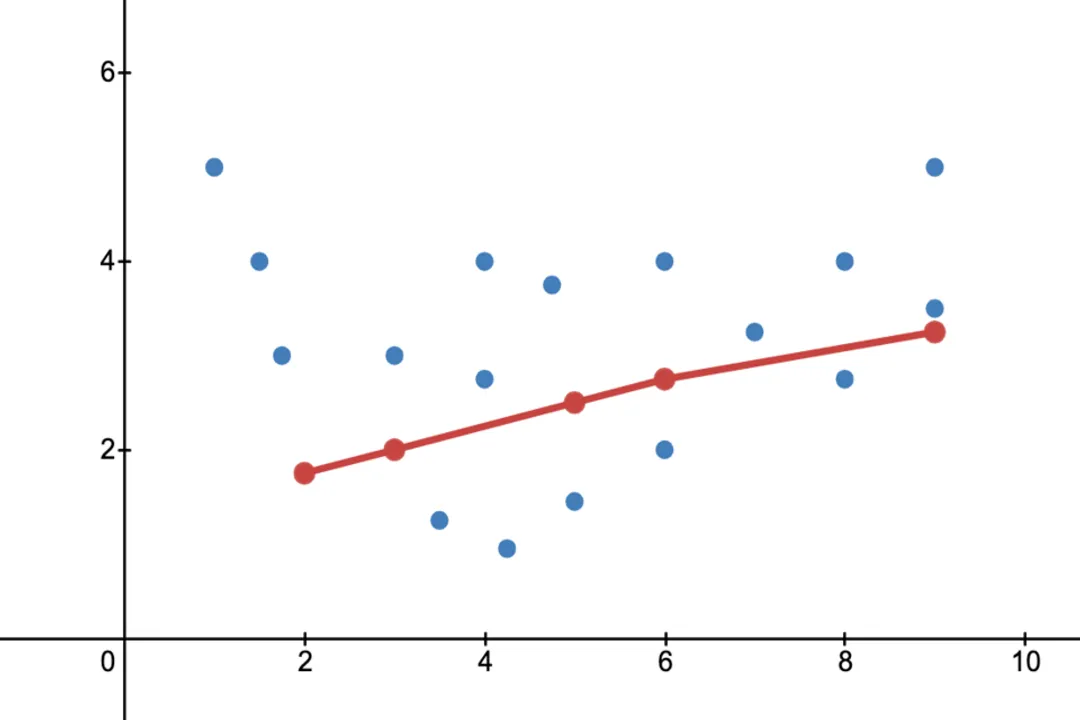
Consider a simple scatter plot of data points. If you use a linear model (low capacity), you will likely get a line that is slightly off from many points, but it captures the general upward trend. If you switch to a polynomial regression model of degree 15 (very high capacity), the resulting curve will snake through the plot, hitting nearly every single point exactly, but it will oscillate wildly between the points, making any prediction just slightly outside the original data range highly unreliable. [5] The complexity allows the model to find spurious correlations that simply do not exist in the broader population the data was sampled from. [6]
# Data Limitations
While model complexity sets the potential for overfitting, limitations in the training data often act as the catalyst that forces the model into this state. [1]
# Insufficient Volume
A primary factor is simply not having enough data. [1][7] If the training set is too small, the model doesn't encounter enough varied examples to distinguish true underlying structure from random chance. [5] With limited examples, the model defaults to memorization because there are fewer constraints guiding it toward generalization. [1] Imagine trying to map out an entire country using only three roadside signs—you'll learn those three spots perfectly, but your understanding of the rest of the territory will be based on noise rather than structure.
# Data Quality
Even if the volume is high, poor data quality can induce overfitting. [1] Real-world data is rarely pristine; it contains errors, input mistakes, or measurement noise. [5][7] An overly complex model, searching for perfect accuracy, will mistake this inherent noise for meaningful information and model it explicitly. [1] This is like a student studying for a test by memorizing every typo in the textbook; they will score perfectly on a test containing the same typos but fail when given correctly printed questions. [7]
When comparing data volume versus quality, one must consider the efficiency of the learning process. Imagine two scenarios: Model A trained on 1,000 perfectly labeled, clean examples, and Model B trained on 10,000 examples riddled with 20% mislabeling. Model A, despite having less volume, might generalize better if its complexity is appropriately constrained, because Model B's capacity will be forced to model the errors in the extra 9,000 points. [1][5] This suggests that rigorous data cleaning and curation efforts can sometimes provide a more effective regularization effect than simply adding more, potentially noisy, data points.
# Training Dynamics
The how and how long of the training process also dictate whether overfitting takes hold. [7]
# Prolonged Training
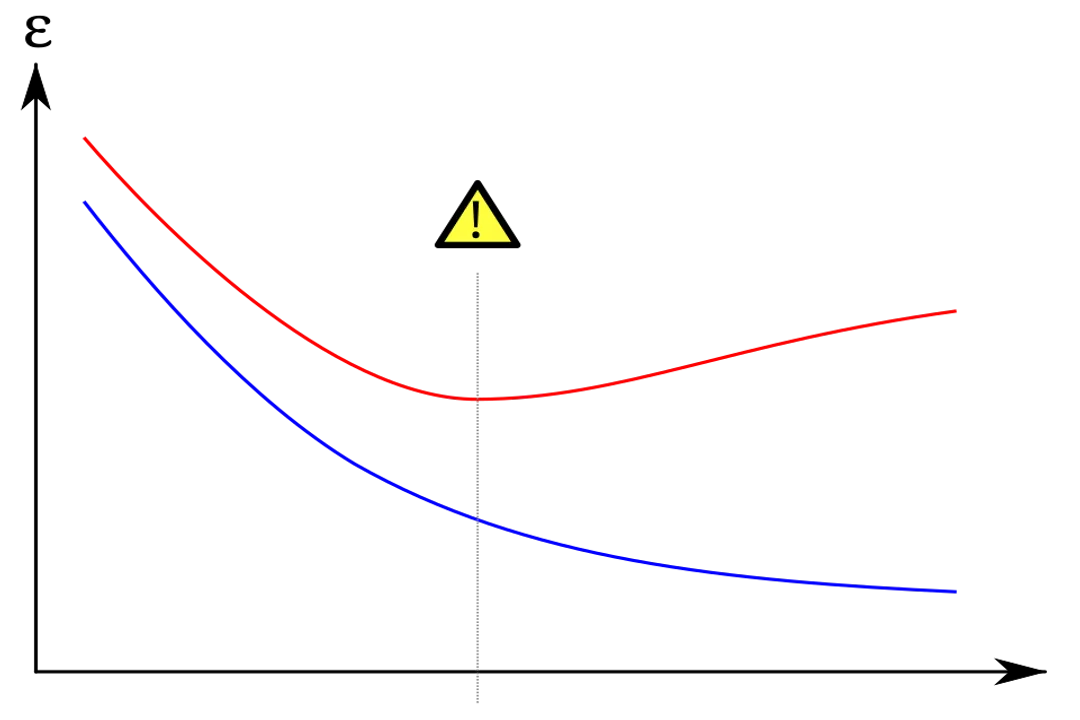
In iterative training algorithms, like gradient descent used for neural networks, the model starts by learning the broad, general trends first—this is the low-error, high-signal phase. [7] However, if training continues past this optimal point, the model starts fine-tuning itself to the specific noise embedded in the training batches. [5][6]
The tell-tale sign of this dynamic is observing the error metrics over time. The training error will continue to decrease or remain near zero, but the validation error—the measure of how well the model performs on data it hasn't seen yet—will eventually plateau and then start to increase. [7] This point of divergence is precisely where generalization capability has peaked, and overfitting has begun. [6]
# Feature Space Dimensionality
Overfitting is not just about the total number of parameters in the model architecture; it is critically linked to the dimensionality of the feature space relative to the number of observations. [6] When you have far more input features (dimensions) than you have training samples, the model essentially has vast mathematical freedom in that high-dimensional space to perfectly separate the few points it has seen. [6] This mathematical freedom makes the model highly susceptible to finding spurious correlations between features that happen to align perfectly within the small training sample but hold no predictive power outside of it. [6] This is why techniques that reduce the number of input features often act as an implicit, helpful form of regularization.
# Contextualizing the Problem
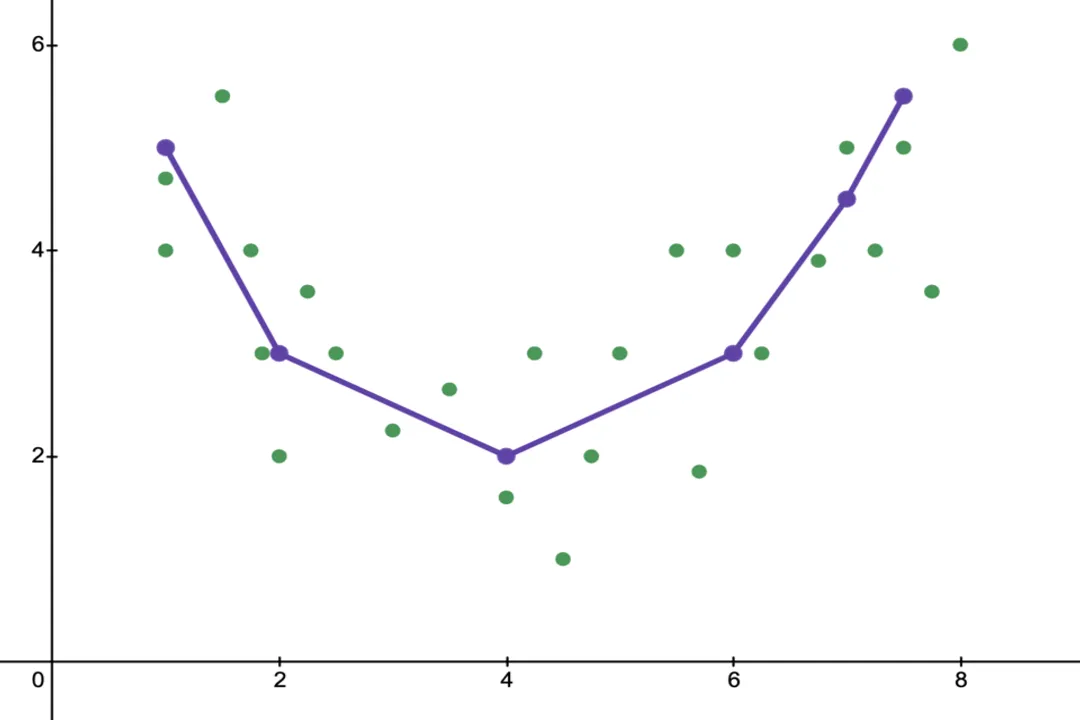
Overfitting is best understood within the context of the bias-variance tradeoff. [6][7]
# Variance and Sensitivity
Overfitting is fundamentally characterized by high variance. [6][7] A high-variance model is overly sensitive to the specific data points in the training set. If you were to train the exact same model architecture twice, but with two slightly different samples drawn from the same underlying data distribution, the resulting high-variance models would look dramatically different from each other. [5] This instability shows the model is latching onto sample-specific noise rather than stable, general patterns. [6]
# The Contrast with Underfitting
To fully grasp overfitting, it helps to contrast it with its opposite problem: underfitting. [4][6] Underfitting happens when the model is too simple—it has too little capacity or is too constrained to capture the essential relationships present even in the training data. [4] This results in high error on both the training set and the test set because the model failed to learn the basic signal. [6]
A helpful way to visualize this is a three-tiered approach:
| Model State | Training Error | Test Error | Primary Issue |
|---|---|---|---|
| Underfitting | High | High | Model too simple (High Bias) |
| Good Fit | Low | Low (similar to training) | Balanced complexity |
| Overfitting | Very Low | High | Model too complex (High Variance) |
The entire goal of effective model development is to hit that "Good Fit" target, where complexity matches the inherent structure of the problem, allowing generalization without memorization. [7]
# Identifying the Symptoms
Detecting the causes often begins with observing the symptoms, which manifest clearly during validation. [7] The most telling symptom is the failure of the test error to mirror the success of the training error. [7] If you are tracking performance across training epochs, you are looking for the crossover point where the validation loss stops decreasing and begins its ascent, while the training loss continues its downward trajectory. [7] This divergence confirms that the resources being spent on training are now dedicated to noise reduction rather than signal reinforcement. [1] Monitoring this gap actively allows practitioners to halt training or apply corrective measures before the model becomes irrevocably fixated on the training set specifics. [7]
Related Questions
#Citations
What is Overfitting? - Overfitting in Machine Learning Explained - AWS
Overfitting: Causes and Remedies - Towards AI
What is Overfitting? | IBM
Underfitting and Overfitting in ML - GeeksforGeeks
Overfitting - Wikipedia
Understanding the Causes of Overfitting: A Mathematical Perspective
Overfitting in Machine Learning Explained - Encord
What are the causes of overfitting? - Kaggle
Understanding Overfitting in Machine Learning: Causes, Impacts ...